Rolumns v1.3 & Recompose v1.0
By Cariad Eccleston • 👋 @cariad@indiepocalypse.social • ✉️ cariad@cariad.earth
I built them, and now you’re going to hear about it.
I updated one of my favourite Python projects and launched a new one this week!
Rolumns 1.3
Rolumns is my Python package for manipulating structured data into lists of rows and columns. As you might guess, I built it to rearrange JSON responses from APIs into specific rows and columns to be sent to Markdown table and spreadsheet renderers.
Rather than get bogged down in n-dimensional grouped repeating data, Rolumns asks you to describe your root set of non-repeating rows, then allows you to attach a single grouper – be it repeating data, or data pivoted ninety degrees as user-defined fields, or so on. A single grouper might seem restrictive, but in the context of each grouper, it’s dealing only with non-repeating rows, which means you can add a grouper to them. In fact, you can chain groups as wide as you like.
So, for example, let’s say you’ve got this data:
{
"company": {
"name": "Pringles IT Services"
},
"staff": [
{
"name": "Robert Pringles",
"email": "bob@pringles.pop",
"title": "CEO"
},
{
"name": "Daniel Sausage",
"email": "danny@pringles.pop",
"title": "Head Chef"
},
{
"name": "Charlie Marmalade",
"email": "charlie@pringles.pop",
"title": "CTO"
}
]
}
…and you want to rearrange it into a row per staff member, but also pivot their email address and title into user-defined fields.
The code for that would look like this:
from rolumns import ByUserDefinedFields, Columns
from rolumns.renderers import RowsRenderer
columns = Columns()
staff = columns.group("staff")
staff.add("Name", "name")
by_udf = ByUserDefinedFields()
by_udf.append("Email", "email")
by_udf.append("Title", "title")
udfs = staff.group(by_udf)
udfs.add("Property", ByUserDefinedFields.NAME)
udfs.add("Value", ByUserDefinedFields.VALUE)
renderer = RowsRenderer(columns)
rows = renderer.render(data)
…and rows ends up looking like this:
[["Name", "Property", "Value"],
["Robert Pringles", "Email", "bob@pringles.pop"],
["Robert Pringles", "Title", "CEO"],
["Daniel Sausage", "Email", "danny@pringles.pop"],
["Daniel Sausage", "Title", "Head Chef"],
["Charlie Marmalade", "Email", "charlie@pringles.pop"],
["Charlie Marmalade", "Title", "CTO"]]
Not bad! I’m using Rolumns in a proprietary reporting framework for a client, and it’s been working just great… until the latest report designs came in.
Repeating non-repeating data in a repeating group
One of my client’s clients wants to repeat values from the root data set inside the user-defined fields, but that just wasn’t possible in Rolumns. The user-defined fields had to be grouped by staff member, and so the only data available to them was within each iteration of the “staff” list.
After a bit of thought, I released Rolumns 1.2 with cursors. Now each column set has a cursor property that exposes its current record set, and each column’s source cursor can be overridden at design-time.
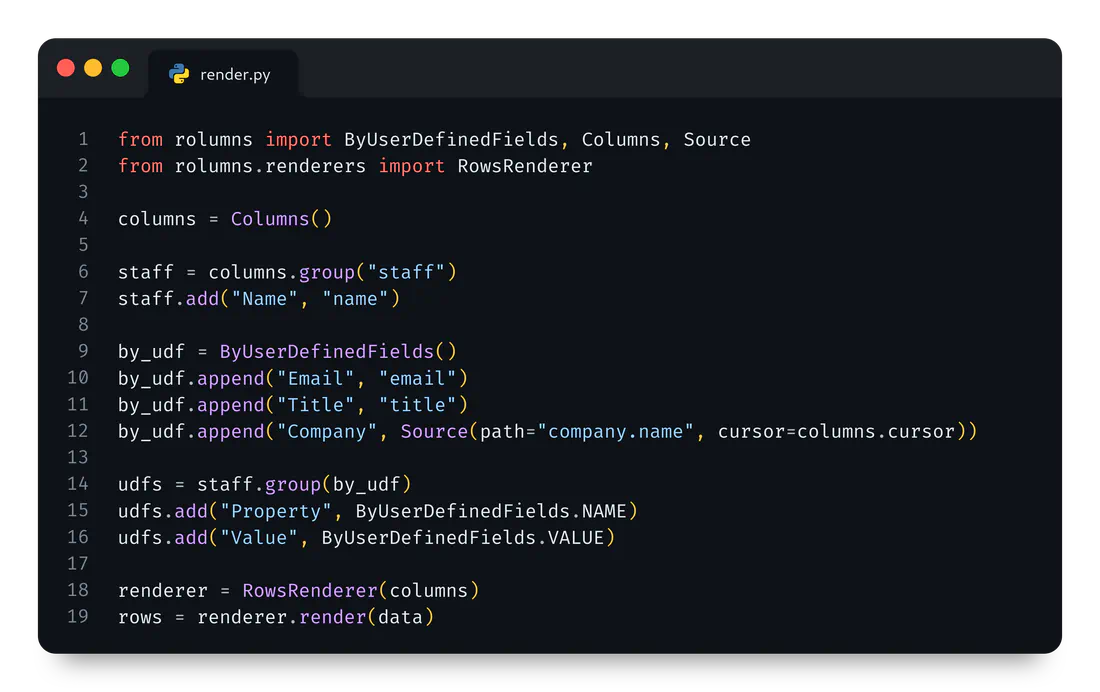
And so, we can update the example above to include the static company name in each staff group like this:
from rolumns import ByUserDefinedFields, Columns, Source
from rolumns.renderers import RowsRenderer
columns = Columns()
staff = columns.group("staff")
staff.add("Name", "name")
by_udf = ByUserDefinedFields()
by_udf.append("Email", "email")
by_udf.append("Title", "title")
# The new user-defined field:
by_udf.append(
"Company",
Source(path="company.name", cursor=columns.cursor),
)
udfs = staff.group(by_udf)
udfs.add("Property", ByUserDefinedFields.NAME)
udfs.add("Value", ByUserDefinedFields.VALUE)
renderer = RowsRenderer(columns)
rows = renderer.render(data)
And now, rows looks like this:
[["Name", "Property", "Value"],
["Robert Pringles", "Email", "bob@pringles.pop"],
["Robert Pringles", "Title", "CEO"],
["Robert Pringles", "Company", "Pringles IT Services"],
["Daniel Sausage", "Email", "danny@pringles.pop"],
["Daniel Sausage", "Title", "Head Chef"],
["Daniel Sausage", "Company", "Pringles IT Services"],
["Charlie Marmalade", "Email", "charlie@pringles.pop"],
["Charlie Marmalade", "Title", "CTO"],
["Charlie Marmalade", "Company", "Pringles IT Services"]]
Nice! It fit in our reporting framework beautifully, and life was good again… for about two minutes.
Constant value columns
As well as plucking data across groups, the client also needed a column with a static constant value – as in, a hard-coded value, not a value read from the data source.
I considered just adding that functionality to the reporting framework rather than Rolumns. But then I figured, why not?
So now in Rolumns 1.3, right alongside where you’d override a column’s cursor, you can also specify a constant binding:
by_udf.append(
"Is a Good Employee?",
Source(constant="Yes"),
)
Double-nice! And with that, Rolumns 1.3 is published, documented and ready to install.
Recompose 1.0
While those two new reporting requirements went in just fine, Rolumns wasn’t the right home for the third. The client had a data set with a list of records, but wanted only the first in the list to be reported on.
Now sure, I could put some kind of filter definition on the new cursors, but my gut whispered to me: if Rolumns is reporting on more records than the client needs, then the data is describing more records than the client needs. Clean the data before reporting on it.
Rather than spend too long in analysis paralysis, I committed to splitting data cleansing into a separate project with three specific, minimum viable product requirements:
- It must be possible to select a specific list deep within a dictionary. No other navigation is required right now.
- It must be possible to collapse a given list into just its first value. No other manipulation is required right now.
- It must be possible to describe the navigation and manipulation via configuration so that it can be included as metadata in our custom report schemas. Programmatic transformations are not required right now.
I spent this last Saturday hacking out some ideas, and I settled on Recompose; a Python package for recomposing data by following instructional schemas.
Let’s start with the most basic example; we just have a list of values, and so no navigation through the data is required:
["one", "two", "three"]
To collapse that list down to a single value using Recompose, we can apply this schema:
{
"version": 1,
"perform": "list-to-object"
}
The version is just the schema version, and perform describes the transformations to apply. When there’s only one transformation–as there is in this case–then we can forego the list of transforms and just pass the one to perform.
And when we perform the transformation via this code…
from recompose import transform, CursorSchema
transformed = transform(schema, data)
…transformed simply has the string value "one".
Too easy, so let’s add some depth. Let’s say now we have a dictionary of lists:
{
"first": ["one", "two", "three"],
"second": ["four", "five", "six"],
"third": ["seven", "eight", "nine"]
}
…and let’s say we want to transform it into a dictionary of single values.
In the first example, we manipulated the root data, but this time we want to manipulate the values of each child in the data:
{
"version": 1,
"on": "each-value",
"perform": "list-to-object"
}
The only difference here is the addition of the on property, which describes the cursor to create to move through the data. The first example used a “this-value” cursor, but we didn’t need to mention it in the schema because it’s the default. This time, we have to include it, and the result is:
{
"first": "one",
"second": "four",
"third": "seven"
}
Okay! For our third and final trick, we’ll navigate through the dictionary to find the list to collapse. Here’s our data:
{
"2023-06-04": {
"groups": {
"chefs": [
{
"name": "Alice"
},
{
"name": "Bob"
}
],
"firefighters": [
{
"name": "Daniel"
},
{
"name": "Esther"
}
],
"zookeepers": [
{
"name": "Gregory"
},
{
"name": "Harold"
}
]
}
},
"2023-06-05": {
"groups": {
"chefs": [
{
"namQe": "Jet"
},
{
"name": "Karen"
}
],
"firefighters": [
{
"name": "Mater"
},
{
"name": "Nigel"
}
],
"zookeepers": [
{
"name": "Peter"
},
{
"name": "Quentin"
}
]
}
}
}
…and let’s say we want to reduce each group’s list of firefighters to a single value.
Here’s the schema to achieve that:
{
"version": 1,
"on": "each-value",
"perform": {
"transform": "pass",
"path": "groups",
"cursor": {
"perform": {
"transform": "pass",
"path": "firefighters",
"cursor": {
"perform": "list-to-object"
}
}
}
}
}
There’s a lot going on in there, so let’s break it down.
- The initial cursor is an “each-value” because the root object is a dictionary and we want to modify its contents (as opposed to a “this-value” cursor which would modify the dictionary itself).
- That initial cursor performs a “pass” transformation on the incoming data. A “pass” doesn’t modify any data, but allows it to be sectioned and passed into a further cursor. In this case, the “path” property directs Rolumns to pass only the value of the “groups” key into the next cursor.
- This second cursor doesn’t have an “on” condition, so it’s inferred to be “this-value” – so the value itself (the value of the “groups” key, if you remember).
- This second cursor performs another “pass” transformation, which drills into the “firefighters” key.
- The final cursor, once again, has an inferred “this-value” cursor, so it’s going to modify the list of firefighters rather than modify each firefighter individually. And the “list-to-object” transformation is applied, which reduces the list of firefighters to a single value.
In the end, the result of this schema on this data is:
{
"2023-06-04": {
"groups": {
"chefs": [
{
"name": "Alice"
},
{
"name": "Bob"
}
],
"firefighters": {
"name": "Daniel"
},
"zookeepers": [
{
"name": "Gregory"
},
{
"name": "Harold"
}
]
}
},
"2023-06-05": {
"groups": {
"chefs": [
{
"name": "Jet"
},
{
"name": "Karen"
}
],
"firefighters": {
"name": "Mater"
},
"zookeepers": [
{
"name": "Peter"
},
{
"name": "Quentin"
}
]
}
}
}
This is identical to the input data, except for each group’s list of firefighters being reduced.
It’s a bit of mucking around for a “simple” operation, I grant you, but the schema-based approach is really going to help with the specific use-case I built this for, and it’s going to be extensible if/when I need it to be.
Recompose 1.0 is published, documented and ready to install.